はじめに

この記事では日本語のような複雑な言語に特化したモデル「Swallow」について解説します。
Swallowは日本語の複雑性と特異性に対応するために開発されたモデルで、東京工業大学と産業技術総合研究所によって共同開発されました。
Swallowは、英語に特化した既存のモデルをベースに、日本語処理の能力を大幅に強化したものです。
この記事では、Swallowの開発背景、特徴、そして私たちの日常生活やビジネスに与える影響について深く掘り下げていきます。
ぜひ最後までお読みください。
ARCHETYP Staffingでは現在クリエイターを募集しています。
エンジニア、デザイナー、ディレクター以外にも、生成AI人材など幅広い職種を募集していますのでぜひチェックしてみてください!
Swallowとは何か?

引用元:https://tokyotech-llm.github.io/swallow-llama
「Swallow」とは、日本語に特化した最新の大規模言語モデルです。
このモデルは、英語中心の言語理解能力を持つ大規模モデルであるMeta社のLlama 2をベースに開発されました。しかし、Swallowの特徴は、Llama 2の基本構造を踏襲しつつも、日本語処理に特化した強化が施されている点にあります。
モデルのサイズと構成
Swallowは、複数の異なるサイズのモデルが存在します。
具体的には、70億、130億、そして700億のパラメータを持つバージョンがあり、これらの大規模なパラメータ数は、複雑な言語パターンを理解し、より正確な言語生成が可能になることを意味します。
これにより、日常的な会話から専門的なテキストまで、幅広い日本語コンテンツの処理が可能になります。
日本語能力の強化
Swallowの開発において重要な点は、日本語の特性を深く理解し、それに対応するための独自のデータセットの構築です。
従来の多言語モデルでは、日本語の特殊な文法や表現を十分に捉えることが困難でしたがSwallowでは、日本語のリッチな表現力に対応するために、新たに開発された大規模な日本語コーパスを使用しています。これにより、日本語の細かいニュアンスや複雑な文脈も適切に処理することが可能となりました。
実用性と応用
Swallowの開発は、単に技術的な成果にとどまらず、実際の応用においても大きな影響を与えています。このモデルの活用により、チャットボット、翻訳システム、コンテンツ生成など、様々な分野で日本語処理の質が向上することが期待されています。また、商用利用も可能であり、企業や研究機関での利用が進むことで、日本語のAI技術のさらなる発展が促されるでしょう。
開発の動機と目的

言語モデルの進化は、AI技術の中核をなす分野ですが、多くのモデルは英語に最適化されているため、他の言語に対する処理能力が限定的でした。
このような背景の中で、日本語の複雑さと多様性を理解し、処理できるモデルの開発が急務となっていました。そこで、Swallowの開発が始まりました。
日本語は、その文法構造、表現の多様性、および微妙なニュアンスが他の言語に比べて複雑です。
従来の多言語モデルでは、これらの特徴を十分に捉えることができず、日本語特有の表現や文脈を正確に理解することが困難でしたがこの問題を解決するために、Swallowは日本語の特性に特化して設計されました。
目的:日本語処理能力の強化
Swallowの主な目的は、日本語の自然言語処理を強化し、より精度高く、自然な日本語の理解と生成を可能にすることです。
これにより、日本語を使用するユーザーがAI技術をより効果的に活用できるようになります。また、日本語の文化的な要素や独特な表現をAIが理解し、反映できるようになることで、より豊かなコミュニケーションが実現します。
開発の意義
Swallowの開発は、日本語の自然言語処理の可能性を広げるだけでなく、言語多様性に対するAI技術の応用範囲を拡大する重要な一歩です。
日本語を含む多言語対応のアプリケーションやサービスの開発が進むことが期待され、言語の壁を越えたグローバルなコミュニケーションと情報交換が促進されます。
技術的な革新
引用元:https://tokyotech-llm.github.io/swallow-llama
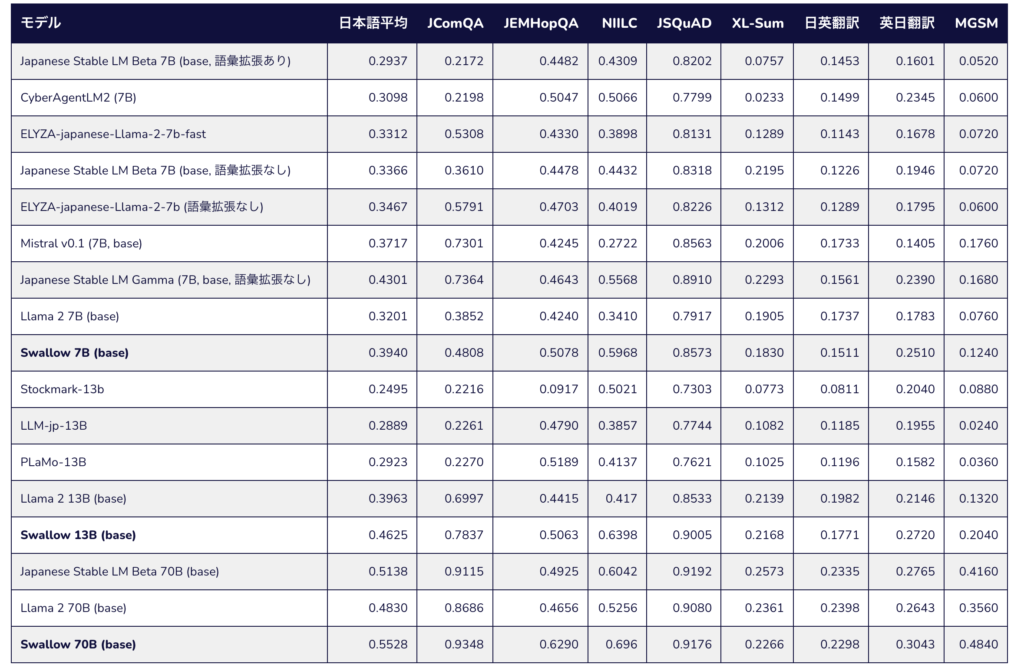
Swallowは、既存の言語モデルの枠組みを大きく進化させる技術的な革新を達成しました。
このセクションでは、その主な技術的な革新点と、日本語処理能力の強化について掘り下げます。
継続事前学習の採用
Swallowの開発では、継続事前学習(Continuous Pre-training)という手法が採用されました。
これは、既に高い言語処理能力を持つLlama 2モデルを基に、さらに日本語のデータで追加の事前学習を行う方法です。これにより、モデルは英語中心のデータから学んだ知識を保持しながら、日本語の独特な表現や文脈に対応する能力を獲得しました。
独自の日本語コーパスの構築
Swallowのもう一つの重要な革新は、独自に構築された大規模日本語コーパスの使用です。
このコーパスは、Web上の日本語テキストを広範囲にわたって収集し、精錬したもので、商用利用が可能な中では最大規模とされています。
この豊富なデータセットにより、Swallowは日本語の多様な表現や最新の用語を網羅的に理解することができます。
日本語処理能力の強化
Swallowは日本語の複雑な文法構造や表現をより正確に理解し、自然な日本語生成を行うことが可能になりました。
具体的には、日本語特有の文法ルールや表現のニュアンスを捉える能力が強化され、より人間に近い自然な会話やテキスト生成が実現できるようになりました。
商用利用とライセンス

Swallowの日本語処理能力により、商用環境でも広く注目を集めています。
このセクションでは、Swallowの商用利用可能性と、関連するライセンス条件について解説します。
商用利用の範囲
Swallowは、LLAMA 2 Community Licenseの下で提供されています。このライセンスでは、月間アクティブユーザーが7億人未満の場合、商用目的での使用が可能です。これにより、中小企業やスタートアップ、研究機関などがSwallowを活用して、日本語対応のアプリケーションやサービスを開発できるようになります。
このライセンスは、ユーザーがSwallowを商用環境で利用する際のガイドラインを提供し、広範な応用を促進します。
まとめ
Swallowの開発は、AIと自然言語処理の分野における大きな一歩であり、日本語の複雑さに特化したこのモデルは、今後、さまざまな分野でのイノベーションを促進することでしょう。
Swallowの進化は、言語の壁を越えたコミュニケーションの進展に寄与し、私たちの日常生活やビジネスに新たな価値をもたらすと期待されています。
ARCHETYP Staffingではクリエイターを募集しています!
私たちはお客様の課題を解決するweb制作会社です。現在webサイト制作以外にも、動画編集者や生成AI人材など幅広い職種を募集していますのでぜひチェックしてみてください!
以下のボタンから募集中の求人一覧ページに移動できます。



