
Mistralが次世代モデル「Mistral 3」を発表しました。最大675Bパラメータを持つMistral Large 3と、エッジ向けのMinistral 3シリーズを含む今回のリリースは、Apache 2.0ライセンスで公開されます。オープンソースでありながらクローズドソース並みの性能を実現した背景とは。
ARCHETYP Staffingでは現在クリエイターを募集しています。
エンジニア、デザイナー、ディレクター以外に、生成AI人材など幅広い職種を募集していますのでぜひチェックしてみてください!
ボタンから募集中の求人一覧ページに移動できます。
Mistral Large 3 — 675Bパラメータが実現する新次元の性能
参照:Mistral
Mistral Large 3は、NVIDIA H200 GPU 3,000基を使ってゼロからトレーニングされた大規模言語モデルです。このモデルが採用するのは「混合エキスパート(MoE: Mixture of Experts)」と呼ばれる仕組みで、モデル内に複数の専門家を配置し、入力内容に応じて最適な専門家を選んで処理を行います。総パラメータ数は675Bですが、実際に動作する活性パラメータは41Bに抑えられており、巨大なモデルの力を持ちながら効率的に動作するよう設計されています。
このMoEアーキテクチャは、Mistralが2023年に発表したMixtralシリーズ以来の採用となり、Mistralにおける事前トレーニングの大幅な進歩を示すものです。ポストトレーニング後、一般的なプロンプトへの回答性能では市場最高クラスの命令調整済みオープンウェイトモデルと同等の結果を達成しました。
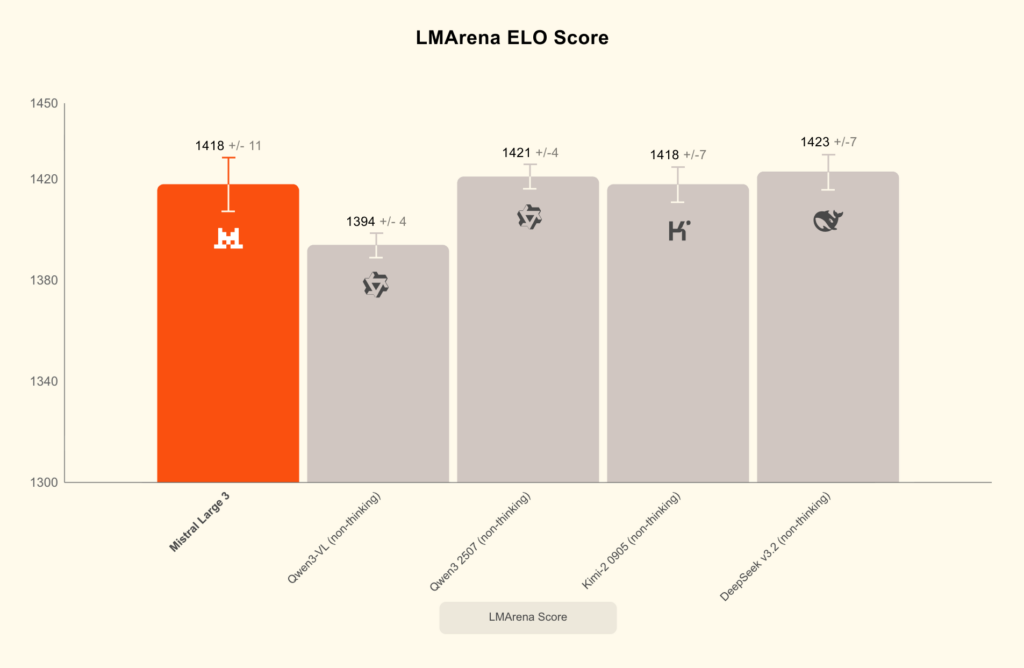
さらに注目すべきは、画像理解機能と多言語対応の強みです。Mistral Large 3は英語や中国語以外の言語での会話において、クラス最高レベルの性能を発揮し、40以上の言語にネイティブ対応しています。性能評価では、LMArenaリーダーボードのオープンソース非推論モデルカテゴリーで第2位にランクインしました。オープンソースモデル全体では第6位という位置づけです。
Mistral AIは、ベース版と命令ファインチューニング版の両方をApache 2.0ライセンスで公開しており、企業や開発者は独自のカスタマイズを加えることができます。推論特化バージョンも近日公開予定です。
では、こうした高性能なモデルを実際に動かすには、どのような環境が必要なのでしょうか。
業界の巨人たちが支える実行環境 — NVIDIA、vLLM、Red Hatとの協業
大規模な言語モデルを実際に動かすには、高性能なハードウェアとソフトウェアの両方が欠かせません。Mistral Large 3は、vLLMとRed Hatとの協力により、オープンソースコミュニティにとってアクセスしやすい形で提供されています。
公開されたモデルデータは、llm-compressorというツールで最適化された圧縮フォーマットになっており、この工夫により強力なサーバーシステム上で効率的に実行できるようになりました。通常、これほど大規模なモデルを動かすには膨大な計算資源が必要ですが、この最適化によってより少ないハードウェアで実行可能になっています。
NVIDIAとの協力も重要な役割を果たしています。Mistral 3シリーズ全体はNVIDIAの最新GPUでトレーニングされ、このGPUは大容量の高速メモリを搭載しており、大規模なワークロードに必要な高速データアクセスを実現しています。NVIDIAは、ハードウェア、ソフトウェア、モデルを統合する徹底的な共同設計アプローチを採用しました。NVIDIAのエンジニアは、Mistral 3ファミリー全体に対して推論エンジンの効率的なサポートを実装し、これにより計算コストを削減しながら高い性能を維持できます。Mistral Large 3に対しては、さらに特別な最適化が施されました。NVIDIAは最新のアーキテクチャ向けに専用の処理機能を統合し、入力処理と出力生成を分離して処理する仕組みも追加しています。この分離により、長文を扱う際の処理効率が向上しました。Mistral AIとNVIDIAは、文章生成を高速化する技術でも協力しており、これは次に生成される文章を予測しながら処理を進める手法で、長文や大量の処理が必要な場面で効率的に動作します。
エッジ環境、つまり手元のデバイスで動かす場合も考慮されています。MinistralモデルはさまざまなデバイスやPCで動作するよう最適化されており、開発者は大規模なデータセンターから小型のロボットまで、一貫した環境でこれらのモデルを実行できます。
こうした強力な実行環境が整う一方で、Mistralはエッジデバイス向けの小型モデルも用意しました。
Ministral 3シリーズ — エッジで動く小型モデルの可能性

エッジデバイスやローカル環境での利用を想定して、MistralはMinistral 3シリーズを発表しました。3B、8B、14Bという3つのサイズで展開され、各サイズにベース版、命令版、推論版が用意されています。すべてのバージョンで画像理解機能が搭載され、Apache 2.0ライセンスで公開されています。Ministral 3の最大の特徴は、コストパフォーマンスの高さです。実際の使用場面では、生成される文章の量とモデルサイズの両方が重要になりますが、Ministral命令モデルは同等のモデルと比較して性能が同等以上でありながら、生成する文章量が桁違いに少ないという結果が出ています。つまり、同じ内容を伝えるのに必要な計算量が大幅に削減されているのです。
精度を最優先する場面では、推論バリアントが威力を発揮します。より長く考えることで高い精度を達成しており、14Bバリアントは数学コンテストであるAIME 2025において85%の正答率を記録しました。Mistral 3は、Mistral AI Studio、Amazon Bedrock、Azure Foundry、Hugging Face、Modal、IBM WatsonX、OpenRouter、Fireworks、Unsloth AI、Together AIで既に利用可能です。NVIDIA NIMとAWS SageMakerでも近日中に提供が開始される予定です。
Mistral AIは、独自のニーズに合わせたカスタマイズを求める組織向けに、カスタムモデルトレーニングサービスも提供しています。特定の業務に最適化したり、独自データで性能を向上させたりすることが可能です。
大規模モデルから小型モデルまで、すべてをオープンソースで公開するというMistralの姿勢は、AI開発の選択肢を大きく広げることになるでしょう。
まとめ

いかがだったでしょうか?
Mistral 3は、675Bパラメータの大規模モデルから3Bの小型モデルまで、幅広い用途に対応するラインナップを揃えています。すべてのモデルがApache 2.0ライセンスで公開され、NVIDIA、vLLM、Red Hatとの協力により実行環境も整備されました。オープンソースでありながらクローズドソースに匹敵する性能を実現したMistral 3は、今後のAI開発において重要な選択肢となるでしょう。
ARCHETYP Staffingではクリエイターを募集しています!
私たちはお客様の課題を解決するweb制作会社です。現在webサイト制作以外にも、動画編集者や生成AI人材など幅広い職種を募集していますのでぜひチェックしてみてください!
また、アーキタイプではスタッフ1人1人が「AI脳を持ったクリエイター集団」としてこれからもクライアントへのサービス向上を図り、事業会社の生成AI利活用の支援及び、業界全体の生成AIリテラシー向上に貢献していきます。
生成AIの活用方法がわからない、セミナーを開催してほしい、業務を効率化させたいなどご相談ベースからお気軽にお問い合わせください!
ボタンから募集中の求人一覧ページに移動できます。



