
中国のMoonshotが発表したKimi K2 Thinkingは、オープンソースの思考モデルとして最高峰の性能を記録しました。ツールを使いながら段階的に推論を重ねる「思考エージェント」として設計され、Humanity’s Last ExamやBrowseCompで最高スコアを獲得しています。
ARCHETYP Staffingでは現在クリエイターを募集しています。
エンジニア、デザイナー、ディレクター以外に、生成AI人材など幅広い職種を募集していますのでぜひチェックしてみてください!
ボタンから募集中の求人一覧ページに移動できます。
ベンチマークが示す圧倒的な性能
参照:Moonshot
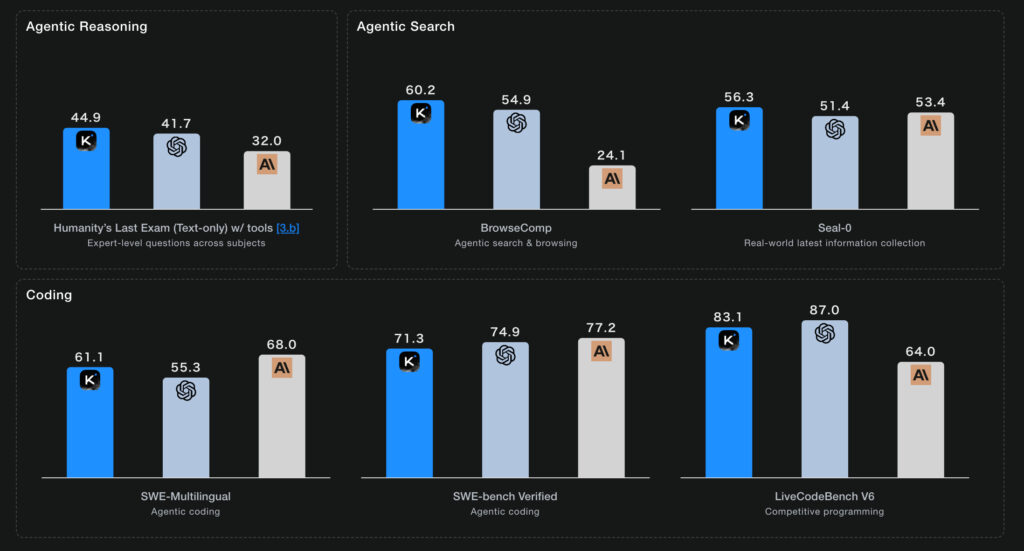
Kimi K2 Thinkingの実力を最も端的に示すのが、各種ベンチマークでの成績です。
Humanity’s Last Exam(HLE)では44.9%というスコアを記録しました。HLEは100以上の科目にわたる数千の専門家レベルの質問で構成されたテストで、物理学、数学、生物学から人文科学まで幅広い分野を網羅しています。K2 Thinkingは検索、Python、ウェブブラウジングといったツールを駆使しながら推論を重ね、GPT-5の41.7%やGrok-4の38.6%を上回りました。ツールを活用することで大幅にスコアが向上しており、単なる知識の暗記ではなく、問題解決のために適切なツールを選択し活用する能力を持っていることがわかります。
ウェブ情報の検索と推論を評価するBrowseCompでは60.2%を記録し、人間のベースライン29.2%を大きく上回りました。このベンチマークは、実世界のウェブ上で発見困難な情報を継続的にブラウズし、検索し、推論する能力を測るものです。たとえば、単一のページには書かれていない情報を複数のソースから集めて統合する必要がある問いが含まれており、K2 Thinkingはこうした実践的な情報収集タスクで高い成果を出しました。
さらに、実際のソフトウェア開発を想定したコーディングのベンチマークでも優れた結果を残しています。SWE-Bench Verifiedでは71.3%、SWE-Multilingualでは61.1%を達成し、現場で発生する実際のバグ修正や機能追加といったタスクへの対応力を示しました。これらの評価では、GitHubの実際のissueとpull requestがベースになっており、教科書には載っていない予測不可能な問題への対処が求められます。特にHTML、React、フロントエンド開発で高い性能を発揮しており、ウェブ開発の現場で即座に活用できる可能性を感じさせる結果です。
評価の透明性にも配慮されています。HLEではo3-miniをジャッジとして使用し、公式設定と同一の条件で実施されました。また、Hugging Faceへのアクセスをブロックすることで、ベンチマークデータの漏洩を防ぎ、公正な比較を実現しています。
これらの高い数値を記録できた背景には、K2 Thinkingが採用する独自のアプローチがあります。
200~300回連続で動き続ける思考プロセス

K2 Thinkingが他のモデルと一線を画すのは、人間の介入なしに最大200~300回の連続したツール呼び出しを実行できる点です。これは思考トークンとツール呼び出しステップの両方をスケーリングする「テスト時スケーリング」という手法で実現されています。
具体的には、問題に直面すると「思考→検索→ブラウザ使用→思考→コード実行」という流れを繰り返します。まず問題を分析し、必要な情報を検索し、ウェブページを閲覧して詳細を確認し、その情報をもとに再度思考を深め、必要であればPythonコードを実行して検証します。重要なのは、各ステップが独立しているのではなく、前のステップの結果を次のステップに反映させながら、目標に向かって段階的に前進していく点です。興味深い事例があります。博士レベルの数学問題を、K2 Thinkingは23回の推論とツール呼び出しを交互に行いながら解決しました。問題を読み解き、関連する定理や公式を検索し、それらを適用して計算を行い、結果を検証し、必要に応じてアプローチを修正する—単に答えを出すだけでなく、数学者が論文を書くときのような「証明のプロセス」そのものを再現したのです。
実用性はコーディングの場面でより明確になります。「ユーザーがタスクを管理できるウェブアプリを作って」という単一のプロンプトを受けると、K2 ThinkingはUI設計を考え、必要なコンポーネントを実装し、データの流れを設計し、スタイリングを適用し、動作確認をする一連の作業を完遂します。開発者が通常何時間もかけて行う作業を、論理的な一貫性を保ちながら自律的に進めていくのです。
HLEでは最大120ステップで各ステップ48,000トークン、エージェント検索タスクでは最大300ステップで各ステップ24,000トークンという制約の中で、K2 Thinkingは最適な問題解決の道筋を見つけ出します。
こうした複雑なタスクをこなす一方で、K2 Thinkingは私たちの日常的な文章作成でも力を発揮します。
ライティング能力と推論効率の両立

技術的な問題解決だけでなく、K2 Thinkingは文章作成においても優れた能力を発揮します。
小説や詩といった創作では、詩的なイメージがより深い連想を持つようになり、物語や脚本はより人間的で感情的な内容になりました。ビジネスメールから友人への手紙まで、求められる文脈に応じて適切に書き分けることができます。
ビジネス文書や学術論文といった実用的な文章では、推論の深さと視点の広さが向上しています。プロンプトで指示されたすべてのポイントを網羅的に扱い、それぞれを十分に掘り下げるため、包括的な文書作成に適しています。たとえば「市場分析レポートを作成して」という指示に対して、K2 Thinkingは複数の角度から情報を整理し、論理的に一貫性のある文章を構築します。
キャリアの悩みや人間関係の相談といった個人的な質問に対しては、より共感的でバランスの取れた応答をします。一方的なアドバイスではなく、複数の視点を提示しながら、相談者自身が判断できるような材料を提供します。
そして、これらの高い性能を維持しながら、実用性も確保されています。K2 Thinkingはポストトレーニング段階で量子化認識トレーニング(QAT)を採用し、MoE(Mixture of Experts)コンポーネント—複数の専門的なニューラルネットワークを組み合わせた構造—にINT4重み(4ビットの整数表現)の量子化を適用しました。量子化とは、モデルの数値表現を低ビット化することで処理速度を向上させる技術ですが、通常は性能の低下を伴います。しかしK2 Thinkingは、トレーニング段階から量子化を考慮することで、INT4精度でも性能を維持し、生成速度を約2倍に向上させました。
公開されているすべてのベンチマーク結果は、このINT4精度で達成されています。つまり、カタログスペックではなく、実際に私たちが使える状態での性能だということです。高いベンチマークスコアと実用的な処理速度を両立したK2 Thinkingは、オープンソースモデルの新たな可能性を示しています。
まとめ

いかがだったでしょうか?
Kimi K2 Thinkingは、オープンソースの思考モデルとして、ベンチマークでの高い成績、長時間にわたる自律的な推論能力、そして幅広いライティング性能を実現しました。現在、kimi.comのチャットモードで利用可能で、完全なエージェントモードも近日中に提供される予定です。また、Kimi K2 Thinking APIを通じて開発者も利用できます。Moonshotがオープンソースとして公開したこのモデルが、今後どのような用途で活用されていくのか、注目が集まります。
ARCHETYP Staffingではクリエイターを募集しています!
私たちはお客様の課題を解決するweb制作会社です。現在webサイト制作以外にも、動画編集者や生成AI人材など幅広い職種を募集していますのでぜひチェックしてみてください!
また、アーキタイプではスタッフ1人1人が「AI脳を持ったクリエイター集団」としてこれからもクライアントへのサービス向上を図り、事業会社の生成AI利活用の支援及び、業界全体の生成AIリテラシー向上に貢献していきます。
生成AIの活用方法がわからない、セミナーを開催してほしい、業務を効率化させたいなどご相談ベースからお気軽にお問い合わせください!
ボタンから募集中の求人一覧ページに移動できます。



