はじめに

この記事では、Appleの「Ferret」という大規模言語モデルについて、その特徴、利点、そして持つ可能性とともに潜在的な課題についても深く掘り下げていきます。
このモデルは、画像とテキストの両方を理解し、それらを組み合わせて質問に答えることができます。
しかし、このような革新的な技術には、メリットだけでなくデメリットも存在します。また、このモデルが私たちの日常生活、ビジネス、研究にどのような影響を与えるかについても考察します。
「Ferret」のウェイト情報が公開されたことで、研究者や開発者はこの先進的なツールをさらに探求し、活用する機会を得ています。この記事を通じて、「Ferret」の世界への足掛かりを提供し、その将来性と我々の生活への影響を探ります。
ぜひ最後まで読んでみてください!
GitHubはこちら
https://github.com/apple/ml-ferret?tab=readme-ov-file#demo
ARCHETYP Staffingでは現在クリエイターを募集しています。
エンジニア、デザイナー、ディレクター以外にも、生成AI人材など幅広い職種を募集していますのでぜひチェックしてみてください!
「Ferret」の概要と背景

「Ferret」とは、AppleとColumbia大学の研究者たちによって開発された、革新的なマルチモーダル大規模言語モデル(LLM)です。
このモデルは、2023年10月に世に出され、画像とテキストの両方を理解し、それらを組み合わせた形で質問に答える能力を持っています。これにより、より複雑で多様なデータ処理が可能になりました。
Ferretの開発は、AI技術の進歩とともに変化する市場の要求に応えるために行われました。
当時、市場にはGoogleのGeminiモデルやMistralのオープンソースモデルなど、さまざまなマルチモーダルLLMが登場していました。しかし、Ferretはこれらのモデルとは一線を画す特徴を持っています。
それは、画像の特定領域を指定して、その領域に関する質問に答える能力です。
このモデルの公開当初、リリースは研究利用に限られており、商用ライセンスは提供されていませんでした。このため、初期の段階では広範な注目を集めることはありませんでした。しかし、その後のAIコミュニティや業界内での反応は、Ferretの重要性と可能性を示唆するものでした。
AppleがFerretを公開した背景には、ローカルLLMの可能性と、それを小型デバイスに搭載することによる革新的な用途があります。Appleは、このモデルをiPhoneに搭載することで、ユーザー体験を大きく変えることを目指しています。さらに、3Dアバターと効率的な言語モデル推論のための新しい技術の開発も発表されました。
「Ferret」と他のAIモデルとの比較

近年、AI技術の分野で大きな進歩が見られ、特に大規模言語モデル(LLM)の開発が盛んに行われています。このセクションでは、Appleの「Ferret」と他の主要なAIモデル、特にGoogleのGeminiモデルやMistralのオープンソースモデルとの比較を通じて、Ferretの特徴と優位性を明らかにします。
GoogleのGeminiモデルとの比較
GoogleのGeminiモデルは、主にPixel Proのようなスマートデバイスに搭載されることを目的としたAIモデルです。
このモデルは、高い言語処理能力を持ち、ユーザー体験の向上に貢献しています。しかし、FerretはこのGeminiモデルと比較して、画像認識とテキスト理解を組み合わせたマルチモーダルな機能を持つ点で一歩進んでいます。
これにより、ユーザーが画像に基づいたより複雑な質問に対しても答えることができるようになります。
Mistralのオープンソースモデルとの比較
Mistralはオープンソース性により、幅広い研究者や開発者に利用されています。
このモデルも高度な言語処理能力を持っていますが、Ferretはここに画像解釈の機能を追加することで、さらに応用範囲を広げています。また、Ferretはオープンソースで公開されており、研究や開発においても活用される余地が大いにあります。
独自性と革新性
Ferretの最大の特徴は、画像の特定領域を指定し、それに基づく質問に答えることができる点にあります。これにより、ユーザーはより直感的に情報を得ることができ、新しいタイプのインタラクションが可能になります。さらに、Ferretはメモリと処理能力の面で最先端の技術を採用しており、高いパフォーマンスを発揮します。
Appleによる大きな一歩

Appleは、「Ferret」の発表により、AI分野におけるその役割を大きく進化させました。
3Dアバターと効率的な言語モデル推論
Appleは、Ferretの発表と同時に、3Dアバター生成と効率的な言語モデル推論に関する2つの新しい研究論文を発表しました。
これらの技術は、ユーザーとのインタラクションをよりリアルで没入感のあるものに変える可能性を秘めています。特に、3Dアバター技術は、仮想現実(VR)や拡張現実(AR)の分野での応用が期待されており、ユーザー体験の新たな次元を開くことになります。
iPhoneへのLLMの搭載
さらに、AppleはiPhoneにLLMを搭載することで、スマートフォンの使い方自体を変革することを目指しています。これにより、ユーザーは日常の様々なタスクをより効率的に、かつ直感的に行うことが可能になります。
例えば、写真を見ながらその内容に関する複雑な質問をする、言葉で表現された指示に基づいて写真を分析するなど、これまでにない形でのデバイスとの対話が実現します。
「Ferret」の技術的特徴
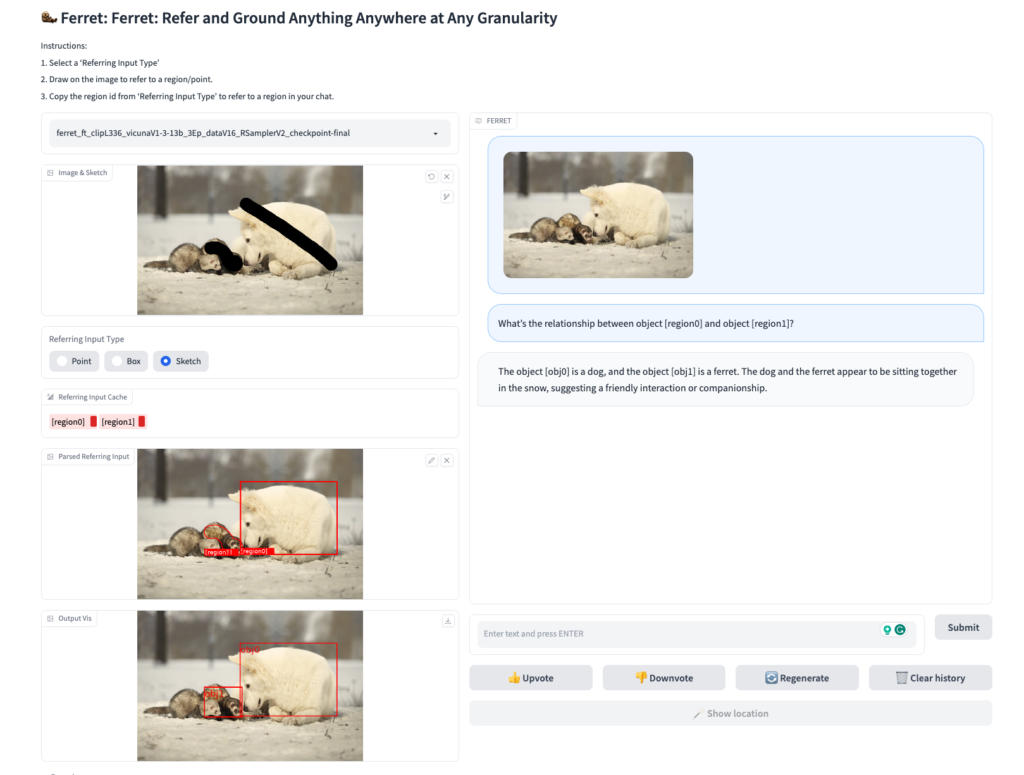
引用元:https://github.com/apple/ml-ferret?tab=readme-ov-file#demo
「Ferret」は、単なる大規模言語モデルを超えた、マルチモーダルな能力を持つAppleの最新技術です。このセクションでは、Ferretの主要な技術的特徴とその革新性について解説します。
画像とテキストの統合
Ferretの最大の特徴は、画像とテキストを組み合わせて処理する能力にあります。
このモデルは、テキストの質問に対して、画像の特定の領域を参照して回答することができます。これにより、例えば「この画像の右上にある物体は何ですか?」といった質問に対して、Ferretはその領域を分析し、正確な回答を提供できます。
領域指定の柔軟性
Ferretは、画像内の特定の領域を「点」、「四角形」、「フリーフォーム」などの方法で指定することができます。
この柔軟性は、ユーザーがより自然な方法で情報を求める際に大きなメリットとなります。
例えば、画像の特定の部分にマーカーをつけて、その部分についての質問をすることが可能です。
言語モデルとのシームレスな統合
Ferretは、高度な言語モデルと画像処理機能をシームレスに統合しています。
モデルはテキストによる質問に対して、画像データを利用して回答することが可能になります。
この統合により、ユーザーはより複雑で多様な情報を得ることができます。
高性能な処理能力
開発には、メモリ80GBのA100 GPUを8個使用しており、これにより高い処理速度と精度を実現しています。
この高性能なハードウェアは、Ferretが大量のデータを迅速かつ効率的に処理することを可能にします。
まとめ
Ferretは、画像とテキストのデータを統合することにより、これまでにないタイプの情報処理能力を実現しています。
このモデルは、特定の画像領域に基づいて質問に答える能力を持ち、ユーザーに対してより豊かで直感的なインタラクションを提供します。
今後も更なる進化が予想されますので、引き続き動向を追っていきましょう!
ARCHETYP Staffingではクリエイターを募集しています!
私たちはお客様の課題を解決するweb制作会社です。現在webサイト制作以外にも、動画編集者や生成AI人材など幅広い職種を募集していますのでぜひチェックしてみてください!
以下のボタンから募集中の求人一覧ページに移動できます。



